Dépôt légal et data.ina.fr : terrain d’expérimentation de l’intelligence artificielle
Le 25 juin dernier lors du festival Cinema Rittrovato qui se tient chaque année en Italie, à Bologne, une table ronde dédiée à l’archivage et à l’IA accueillait Alann Hery, responsable du département des technologies à l’Ina. Il a présenté le projet visant à indexer la colossale quantité d’images et de sons dans le cadre du dépôt légal. Magic Hour était présent : compte-rendu…

À gauche, Alann Hery, responsable du département des technologies (Ina) lors de la table ronde intitulée « IA, point de vue sur le catalogage ».
« Depuis 1995, la mission de dépôt légal a été confiée à l’Ina, lequel enregistre 24 heures sur 24 le flux de 184 chaînes de radio et de télévision. Cette mission a été étendue au Web média en 2009. Aujourd’hui, plus de 27 millions d’heures de programmes sont archivées, complétant un patrimoine historique qui s’élève à près de 30 millions d’heures au total, soit 45 pétaoctets de données — l’équivalent de 3 400 années de visionnage ininterrompu, » résume Alann Hery. responsable du département des technologies à l’Ina. Or décrire un tel volume par des moyens strictement humains est pour ainsi dire irréalisable : « à raison d’une heure de programme finement décrit en six heures de travail de documentaliste, il faudrait près de 180 millions d’heures, soit 100 000 années de labeur pour documenter les 27 millions d’heures que représente le dépôt légal, » explique-t-il. Sans compter les 1,5 million d’heures nouvellement déposées chaque année… Face à ce défi, l’Ina mobilise l’intelligence artificielle pour automatiser la production de métadonnées.
Une ferme de 90 GPU
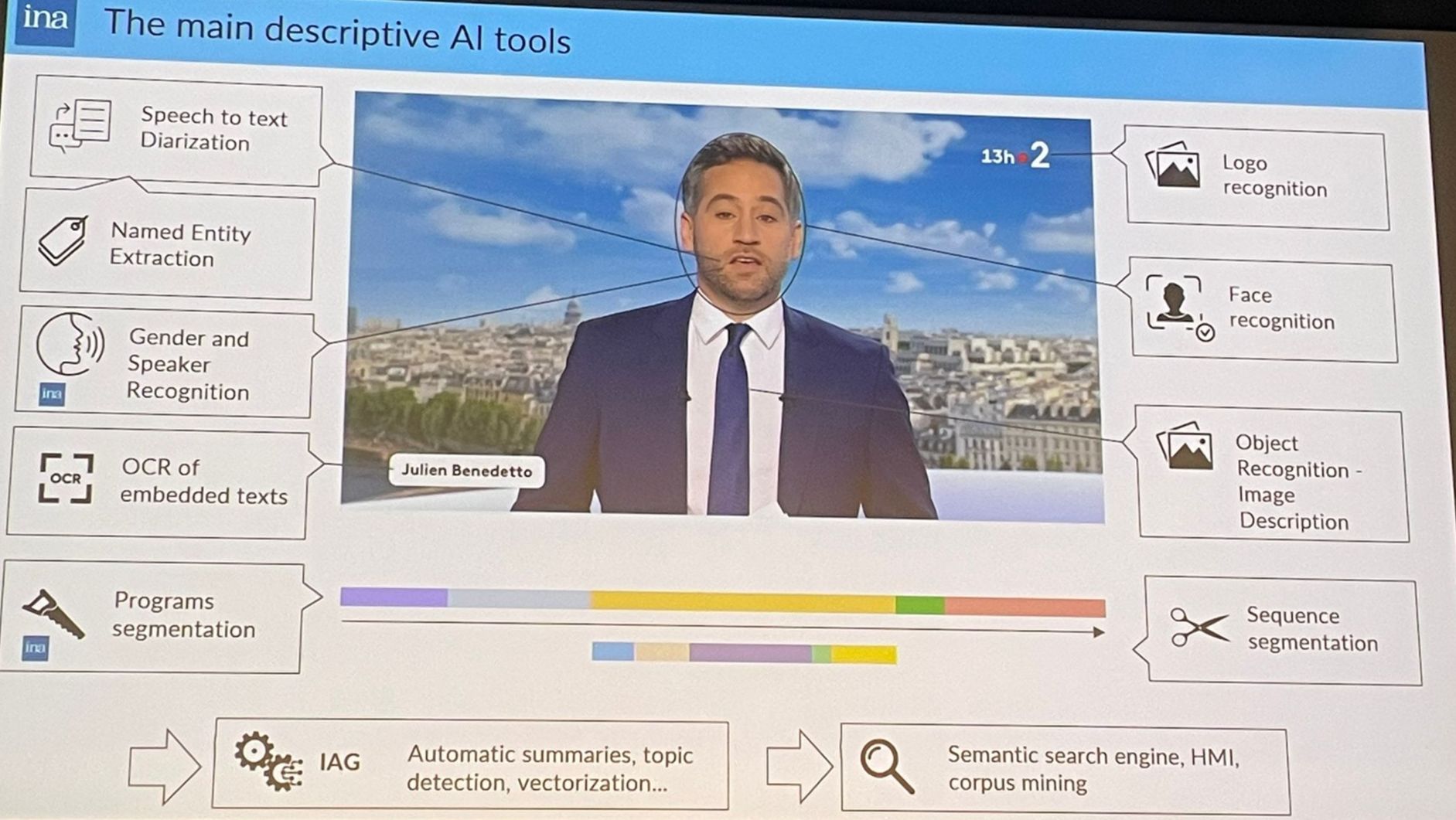
Description des outils IA appliqués sur le JT de France 2.
Dans ce projet de recherche, l’Institut déploie aujourd’hui un parc de 90 GPU travaillant sur le fonds du dépot légal où chaque heure de vidéo est traitée en à peine deux secondes. Le pipeline enchaîne la transcription speech-to-text, la diarisation des intervenants, la segmentation en unités logiques (journaux, reportages, météo), la reconnaissance visuelle des logos, des visages et des objets, ainsi que l’OCR des habillages et la détection d’entités nommées. Les textes obtenus sont ensuite résumés automatiquement et vectorisés, rendant possible une recherche sémantique en langage naturel. Ainsi, grâce à ces algorithmes — existants, mais aussi développés en interne — l’Ina génère chaque jour des sommes de métadonnées inaccessibles au potentiel humain. Pour donner un aperçu de la tâche, le responsable du département des technologies indique : « sur les notices du dépôt légal, 85 % demeurent aujourd’hui sans mot-clé ni résumé. » Seuls les éléments présentant un intérêt majeur bénéficient d’un traitement humain.
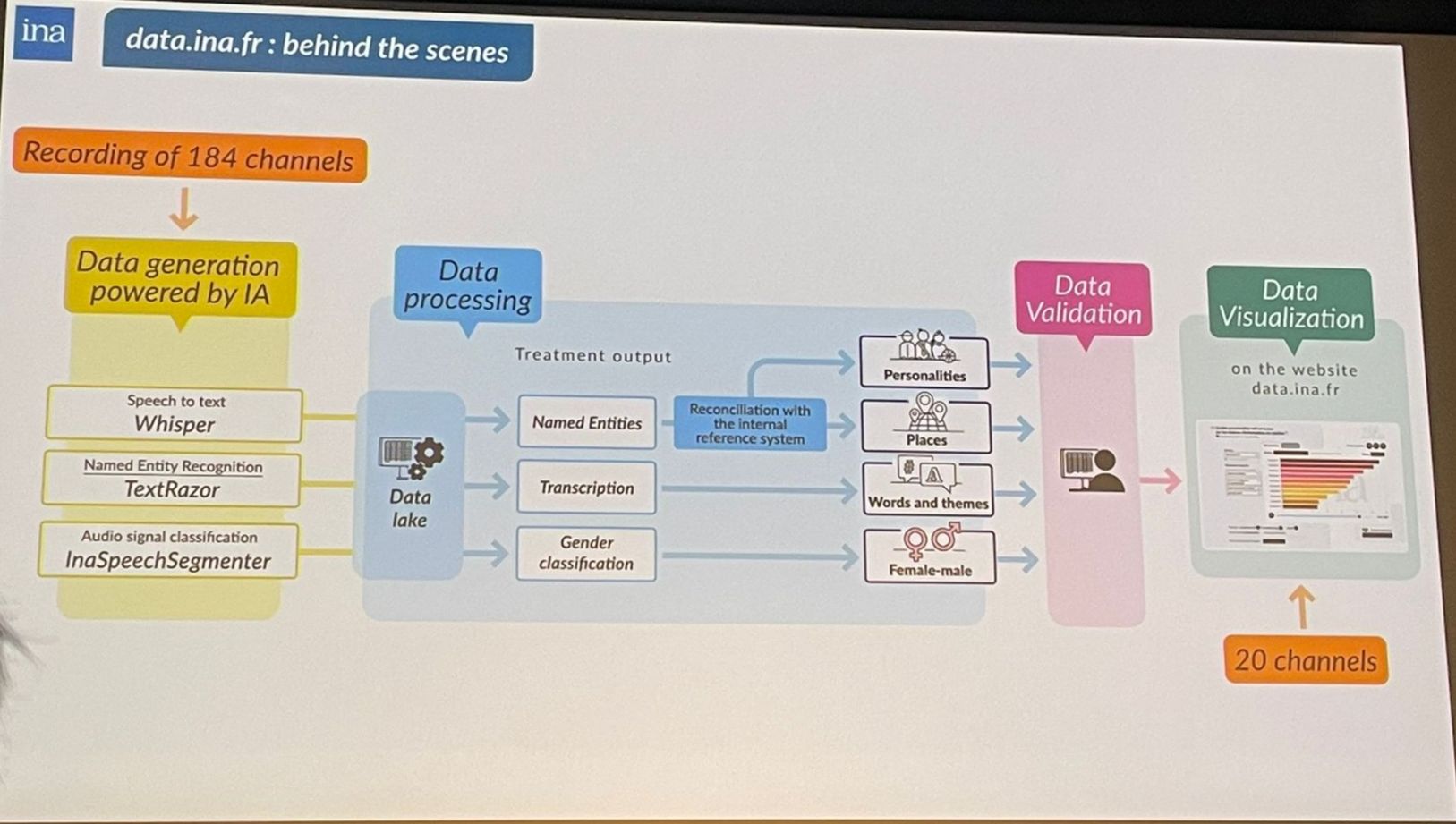
Pipeline de production de métadonnées de l’acquisition à la publication sur data.ina.fr.
Et si l’introduction de l’IA apparaît comme une solution de traitement incontournable, rien ne peut se faire au détriment de la confiance : « Tous les algorithmes ont des biais », avertit Alann Hery. Pour contrôler et documenter ces biais, l’Ina affiche publiquement ses taux de précision : 83 % pour l’extraction d’entités nommées et 95 % pour la détection du genre. Chaque résultat publié est adossé à son extrait d’origine, permettant de remonter à la portion exacte du média source et d’en vérifier la validité. Lorsqu’un algorithme commet une erreur — comme la confusion entre la milice Wagner et le compositeur Richard Wagner — celle-ci reste visible et annotée sur la plateforme, illustrant le souci de transparence et incitant à la vigilance humaine.
Empreinte environnementale maîtrisée
Un autre enjeu, souvent relégué au second plan dans le monde de l’intelligence artificielle, est l’empreinte environnementale : « Faire tourner l’IA sur des data centers, ça consomme de l’énergie et de l’eau », concède Alann Hery. Pour réduire cet impact, l’Ina a choisi de conserver l’ensemble de ses infrastructures en France, où l’électricité est largement décarbonée : « Nos data centers hébergeant les 30 millions d’heures d’archives sont maintenus à 25 °C plutôt qu’à 20 °C, diminuant les besoins en climatisation ; le stockage, quant à lui, repose sur des systèmes peu énergivores. » Grâce à ces décisions — électricité bas carbone, température optimisée et architecture de serveurs à haut rendement — l’empreinte carbone du traitement IA reste maîtrisée. Un effort qui doit être poursuivi à mesure que les volumes augmentent.
Vitrine et terrain d’expérimentation
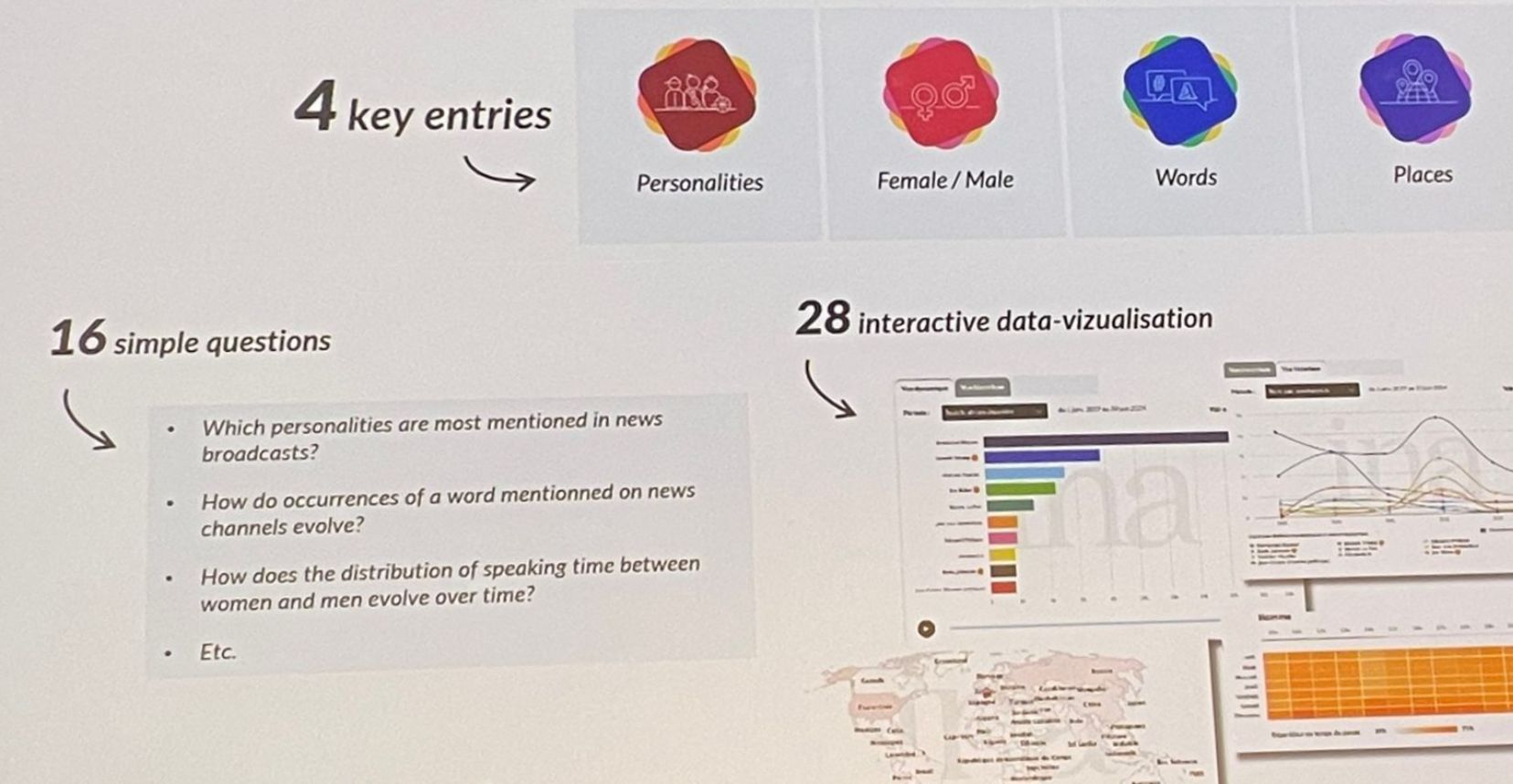
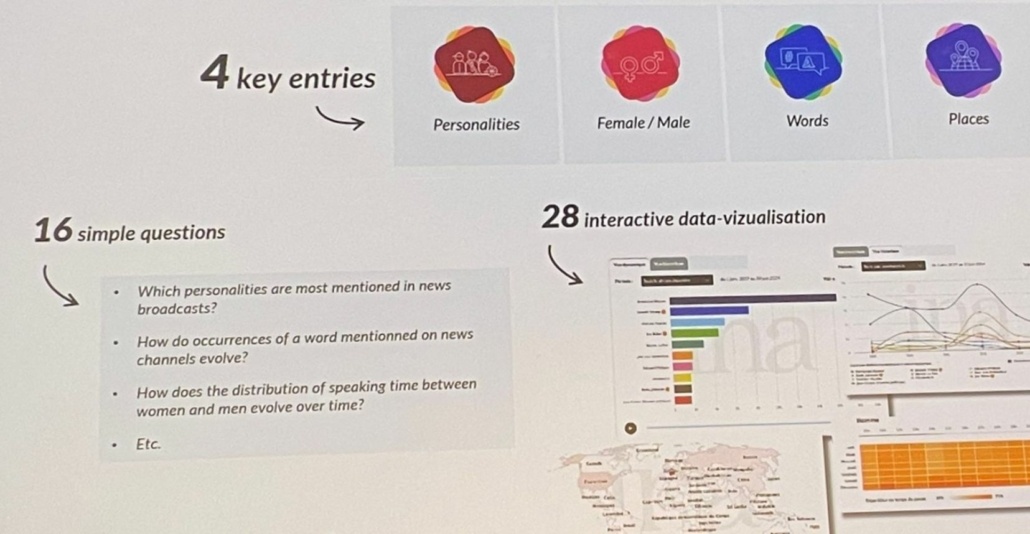
À partir de 4 entrées, les statistiques répondent à 16 questions prédéfinies. data.ina.fr peut sortir jusqu’à 28 types de visualisation des données sur la période 2015-2024. Les applications sont légions, du monde de la recherche à la simple curiosité du grand public.
En octobre 2024, l’Ina a ouvert data.ina.fr, une démonstration concrète de ces outils IA, permettant de faire ressortir tout un tas de données sur les contenus d’information dont le corpus cible les journaux télévisés du soir TF1, France 2, France 3, Arte, les principales matinales radio et les chaînes d’info en continu sur la période 2015-2024. « L’objectif affiché est d’élargir à terme ce corpus avant 2015 », précise Alann Hery. Chaque semaine, plusieurs centaines d’heures de programmes sont intégrées, offrant aux chercheurs, professionnels et grand public la possibilité de naviguer par thèmes, d’identifier des personnalités, de comparer l’évolution des formats et des discours, tout en bénéficiant d’un contrôle humain permanent sur le flux et d’une traçabilité totale.
L’Ina invite à la réflexion